Pour les ménages américains (seulement l’année 2009), ce tableau vu récemment est assez fascinant au regard des conclusions que l’on peut être tenté d’en tirer : 1.bp.blogspot.com/_otfwl2… À ce sujet, sauriez-vous si un tel tableau "statique" existe pour les ménages français ?
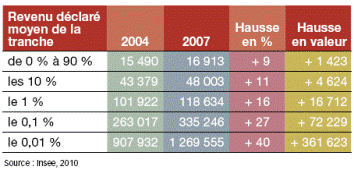
On est carrement dans la fraude intellectuelle (chez Alter-eco et a l’INSEE) ==> moyenne vs mediane (un biais ultra fort pour les 0.01%), et bien sur pas de mention que le nombre des "riches" a augmente de respectivement 28% ( >€100k et et 70% ( >€500k)
Source: http://www.insee.fr/fr/ffc/docs_...
Ces chiffres montrent que les revenu ont peu augmenté (de 9 a 11%) pour 99% des gens. Ils montrent également que la France est très égalitaire puisque qu’une redistribution des revenus égale pour tous augmenterai le revenu des 90% les plus pauvres de 16 913 à 19 558, soit une augmentation d’à peine 15 %.
En effet, les 10% les plus riches ont 22% du total,
les 1% les plus riches ont 7% du total,
les 0.1% les plus riches ont 1.7 % du total,
les 0.01% les plus riches ont 0.75% du total.
Joli… une illustration en courbe de Lorenz ?
Ah, c’est un jeu des sept différences avec l’étude de Camille Landais d’il y a quelques années ? (http://www.inegalites.fr/spip.ph... Ben j’ai pas trouvé.
C’est du revenu imposable, donc, a priori, avant impôt. Ce qui n’est pas forcément la bonne information : quand on s’intéresse à la distribution des revenus, on sous-entend en général que la redistribution par l’impôt pourrait corriger une partie des disparités. Or là, l’effet de la redistribution n’est pas pris en compte.
@jck
Eueueuh !
Vous êtes certain que vous avez tout lu dans le document que vous donnez en référence ?
Parce que le tableau (en bas de p. 46) de l’Insee, en la personne de Julie Solard, donne bien moyenne et médiane et fournit même le rapport entre elles dans les différentes classes (classe, entendue, bien évidemment au sens d’un découpage statistique,…). Où est la fraude ?
Parce que, même au sein des très hauts revenus, ceux-ci sont fortement concentrés sur quelques personnes (p. 46)
Parce que 0,1% de la population s’approprie 4,6% de la croissance (déclarée) des revenus entre 2004 et 2007 (p. 58).
Parce qu’effectivement, l’Insee signale (intertitres, pp. 57-58) :
– une explosion du nombre de personnes riches entre 2004 et 2007…
– … accompagnée d’une explosion des revenus touchés par les personnes à très hauts revenus…
– … d’où une augmentation des inégalités par le « très haut »
(NB : l’Insee est le spécialiste mondial des intertitres qui s’enchaînent !)
On retrouve ce genre de données dans le discours de J.P. Brard à l’assemblée, sur la répartition des richesses en France : http://www.youtube.com/watch?v=Y...
@Simplicissimus:
J’ai bien lu le document au complet, allez voir page 59, tableau 12. L’illustration de l’evolution du revenu par classe est faite en utilisant la moyenne qui ne veut rien dire pour ce type de distribution (re: Mandelbrot et d’autres).
Et ca continue au tableau 13 ==> "en 2004,les plus aises detenaient 0.5% des revenus. Leur part a progresse de 26% en 3 ans" ==> Certainemebnt plus impressionnant que de dire qu’il est passe de 0.5% a 0.63%.
De plus, l’effet redistribution n’est pas pris en compte comme le note Antoine B.
@jck
Oui, je me doutais bien que vous l’aviez lu !-:)
La redistribution, du moins l’imposition sur les revenus (activités et patrimoine), est abordée en p. 51 et dans le tableau 7, en haut de la page suivante où l’on trouve des éléments sur la distribution des taux d’imposition. Je ne suis pas certain que cela modifie sensiblement les conclusions.
Mais, c’est là aussi (dans ces tranches) qu’il faudrait disposer d’une étude sur l’impact du bouclier fiscal.
Enfin, je reviens sur la "fraude", dont je comprends mieux la signification après votre deuxième commentaire. Le message de J. Solard est clair : il y a une augmentation des inégalités par le « très haut » (c’est le dernier intertitre qui joue le rôle de conclusion).
De ce point de vue, il est non seulement logique mais pratiquement indispensable de s’appuyer sur la moyenne plutôt que sur la médiane. Comme le répète tous les enseignements de statistiques descriptives (dont celui que je dispense) :
– "la moyenne est sensible aux valeurs extrêmes, la médiane ne l’est pas".
On peut même dire que, dans ce contexte, retenir la médiane est un choix pseudo-technique, mais à vocation parfaitement idéologique : par construction, elle est faite pour ne pas bouger.
Elle s’intéresse au revenu de l’individu du milieu. Or le classement (le rang) de celui-ci ne sera absolument pas modifié si l’individu le plus riche voit son revenu multiplié par un million. C’est même vrai, si TOUS les individus situés au dessus de lui voient leur revenu multiplié par 10 ! (dans le cas d’un effectif impair, si on veut chicaner, et tous sauf celui juste au dessus dans le cas pair).
Il y a un gros biais sémantique dans l’interprétation des chiffres de cette étude :
On parle des "plus aisés" comme s’ils s’agissait des mêmes entre les deux périodes, même si on apprend qu’entre 2006 et 2007 ils ne sont que 50 % à faire partie des deux échantillons.
Ce qu’il faudrait dire, c’est que les 2 000 foyers les plus aisés ont gagnées 40 % de moins que les 2 000 foyers les plus aisés de 2007 mais qu’on ne dispose pas d’information sur le devenir des revenus des 2 000 foyers les plus aisés de 2004.
Il faut aussi évoquer qu’entre 2004 et 2007 la bourse et les prix immobiliers ont eu une progression de l’ordre de 70 % ; Le chiffre évoqué n’est donc pas étonnant dans la mesure où les plus aisés tirent la plus grand partie de leur revenus de leur capital.
Conclure par une augmentation des inégalités comme le fait alter-eco (et pas l’insee) c’est soit être malhonnête, soit ne pas avoir compris l’étude.
Pour pouvoir le faire, il aurait fallu une étude qui couvre l’intégralité d’un cycle économique : par exemple 2000 – 2007 ou 2003 – 2009 et qui s’intéresse aux individus définis comme les "plus aisés" en début de période, c’est à dire sans changer le périmètre de l’étude chaque année.
@Simplicissimus:
"la moyenne est sensible aux valeurs extrêmes, la médiane ne l’est pas"
Exactement, c’est pour cela que la moyenne n’est pas representative de la "classe" des gens aises pour ce type de distribution statistique (pareto)et quand on analyse l’extreme de la distribution parce que la grande majorite de la "classe" est en dessous de la moyenne. (voir Mandelbrot)
@jck :
Personnellement, dans le cas présent je trouve la moyenne beaucoup plus instructive que la médiane : ce tableau met en valeur les extrêmes (de part le découpage des lignes), choisir la médiane reviendrait à manipuler les chiffres pour gommer les différences.
De plus le terme « fraude » est peut-être un tantinet exagéré…
S’il s’agit de revenus déclarés,il n’est peut-être pas utile de s’exciter sur les décimales pour ce genre de répartition. L’ampleur des revenus non déclarés tout particulièrement dans la tranche 48 000 / 118 000 (car paradoxalement au-dessus la fraude n’est pas nécessaire, au dessous difficile à réaliser pour le salarié lambda) ne peut rendre compte de la réalité des revenus disponibles.
D’autre part , ne pas distinguer revenus du travail et revenus du capital n’éclaire pas le débat.Comme souvent dans Alternatives , polémique et surtout incertain
Des chiffres sur les revenus après impôts sont disponibles sur le site de l’OCDE (oecd.org) il me semble, mais le site est inaccessible pour le moment 🙁
Je me rappelai cette étude pour avoir fait un article dessus en décembre 2009!
Alter éco fait du réchauffé! http://www.insee.fr/fr/themes/do...
Notons cependant que l’étude de l’INSEE porte non pas sur ;la période 2004 2007 mais sur la période 1996 / 2007. Pourquoi ne pas reprendre cette durée qui donne beaucoup plus de sérieux?
il se trouve que sur la période 1996/2007 le revenu moyen du premier décile a augmenté plus fort que les autres (21 contre 17%) mais que le rapport inter décile a baissé (CAD que les inégalités ont diminué) quelque peu….sauf entre 2004 et 2007 (voir graphique 3 sur le document en lien) et comme par hasard ce sont ces dates que choisi Alter Eco
@Verel
Tout d’abord, pour l’éventuel "réchauffé", ce n’est pas AlterÉco, mais bien l’Insee dont il s’agit. Le mensuel ne fait que reprendre l’étude publiée dans l’édition 2010 de "Les revenus et le patrimoine des ménages".
Ensuite, contrairement aux apparences, les sources sont très différentes. Dans le cas de l’étude "longue" (1996/2007), il s’agit d’une enquête par sondage, effectuée sur un panel de 10.000 ménages (cf. note méthodo du document que vous citez en lien). Ce qui ne peut rien donner de sérieux au niveau des "très hauts revenus" où se situe l’étude de J. Solard : là on parle du fractile à 99,99%, soit 1 pour 10.000 ménages. D’ailleurs l’étude de Jérôme Pujol et Magda Tomasini ne descend pas en dessous d’une comparaison des déciles (10% de la population).
L’étude de J. Solard porte sur la totalité des déclarations de revenus, soit de l’ordre de plusieurs dizaines de millions de ménages fiscaux. (le 1 pour 10.000 des ménages concerne environ 5.800 personnes – c’est dans le texte – d’où un nombre de personnes par ménage fiscal de l’ordre de 2 à 3).
L’exploitation statistique exhaustive des déclarations de revenus est, je crois, assez récente et ne devait pas être mise en place en 1996.
@henriparisien
Il ne s’agit, en effet, pas d’un panel avec un suivi longitudinal des ménages, mais de la comparaison des fractiles à deux périodes distinctes. Et l’étude est claire là-dessus, notamment lorsqu’elle parle des "entrants" et des "persistants".
@jck
Nous sommes donc d’accord 😉 puisqu’il ne s’agit justement pas de donner une valeur "représentative de la classe des gens aisés", mais de s’intéresser :
1. à la classe extrême,
2. à l’intérieur de celle-ci, à l’extrêmité supérieure de la classe.
Et d’ailleurs, le rapport (Moyenne/Médiane) qui est fourni dans le tableau 2 est donné ici comme indicateur de la dissymétrie de la distribution. Il mesure très directement le fait que les (très) hautes valeurs tirent la moyenne vers le haut.
Ce qui, avec le fait que ce tirage vers le haut a eu tendance à s’accroître, constitue le fond de l’article,
(mais j’ai l’impression de me répéter…)
Pure coincidence, mais voila un ex. de fraude statistique ==> en trafiquant le revenu de 2 personnes, on montre que le revenu de la "classe" a quintuple, alors qu’il est en baisse de 8.7% http://www.bloomberg.com/news/20...
Eueueuh !
Décidément, on ne comprend pas les mêmes choses !
Apparemment, il s’agit d’une erreur dans la détermination de l’indice "National Average Wage Index" (NAWI), calculé annuellement pour la revalorisation des pensions versées par la Sécurité sociale états-unienne.
Cet indice est calculé par la Sécu à partir d’un échantillon d’environ 151.000 travailleurs (chiffres exacts ici : http://www.ssa.gov/OACT/COLA/awi...
)
et à partir d’un bordereau dit W-2 (formulaire consultable, là : http://www.irs.gov/pub/irs-pdf/f...
déclaration individuelle de revenus transmise à la Sécurité sociale et aux services de la fiscalité locale et fédérale (IRS))
Or, dans la strate des plus de 50 millions de dollars annuels de revenu, sur les 74 travailleurs de l’échantillon NAWI, deux personnes étaient titulaires en 2009 de revenus supérieurs à 32 milliards de dollars. Ce chiffre astronomique résulterait de la multiplicité des déclarations fournies par les déclarants.
Ces valeurs extrêmes sont passées à travers tout le processus de production de l’indice. Elles n’ont été détectées, traitées comme incorrectes, et donc éliminées du calcul, qu’après une première publication de l’indice. D’où le piteux communiqué de la Sécu.
Au passage, ceci laisse entrevoir quelques grosses lacunes dans le processus de production et pourrait justifier l’extrême discrétion du bureau de la Sécurité sociale sur la nature exacte de l’erreur et sur sa non-détection.
Où est la "fraude" ?
Où est le "trafic" ?
Qui est ce méchant "on" qui voudrait à toutes forces "montrer" que les très riches se gavent comme des porcs ?
– Oh le beau cas ! s’exclamerait le Dr Pécule devant un tel loupé de la production statistique. Et merci à jck de l’avoir signalé : je vais de ce pas l’incorporer dans le musée des horreurs que l’on peut laisser passer quand "on ne regarde pas" les données sur lesquelles on travaille.
Enfin, il est certain qu’il y en a quelques uns qui doivent se faire méchamment frotter les oreilles !
@Simplicissimus, dans votre réponse à henriparisien :
l’article d’Altereco s’intitule : "Des riches de plus en plus riches". Le sous-titre est : "
Bonne nouvelle: l’Insee a publié de nouvelles données sur les plus aisés. Mauvaise nouvelle: ils s’enrichissent beaucoup plus vite que le reste de la population."
Clairement, l’article laisse entendre que les populations sont homogènes et que croissance de 40% des revenus du fractile signifie croissance de 40% des revenus des individus.
C’est facheux.
Un commentaire tardif pour non initié : ne pas oublier de préciser que les revenus déclarés du tableau initial sont les revenus du foyer fiscal par "unité de consommation". Exemple : ma déclaration fiscale 2009 est de 65k€, marié, 2 enfants, mon revenu est de 65/2.3=28 k€, je suis dans les 90% (revenus entre 0 et 35.7k€).
De toute maniere, je vois deux biais dans ces tableaux:
1. Lorsque l’on s’intéresse a 0,01% de la population, il semble souhaitable de montrer qui la compose et comment sa composition évolue;
2. Les revenus declarés notamment pour les classes faisant l’horreur des commentateurs dépendent me semble t il de la politique de dividende des entreprises qui composent leur portefeuille boursier. Il me semble qu’il y a incoherence a penser que leur revenu du capital peut avoir augmenter alors que la part de la plus value allant au capital est constante.
Tant mieux pour les riches ! 🙂
Pour les ménages américains (seulement l’année 2009), ce tableau vu récemment est assez fascinant au regard des conclusions que l’on peut être tenté d’en tirer : 1.bp.blogspot.com/_otfwl2… À ce sujet, sauriez-vous si un tel tableau "statique" existe pour les ménages français ?
On est carrement dans la fraude intellectuelle (chez Alter-eco et a l’INSEE) ==> moyenne vs mediane (un biais ultra fort pour les 0.01%), et bien sur pas de mention que le nombre des "riches" a augmente de respectivement 28% ( >€100k et et 70% ( >€500k)
Source:
http://www.insee.fr/fr/ffc/docs_...
Ces chiffres montrent que les revenu ont peu augmenté (de 9 a 11%) pour 99% des gens. Ils montrent également que la France est très égalitaire puisque qu’une redistribution des revenus égale pour tous augmenterai le revenu des 90% les plus pauvres de 16 913 à 19 558, soit une augmentation d’à peine 15 %.
En effet, les 10% les plus riches ont 22% du total,
les 1% les plus riches ont 7% du total,
les 0.1% les plus riches ont 1.7 % du total,
les 0.01% les plus riches ont 0.75% du total.
Joli… une illustration en courbe de Lorenz ?
Ah, c’est un jeu des sept différences avec l’étude de Camille Landais d’il y a quelques années ? (http://www.inegalites.fr/spip.ph... Ben j’ai pas trouvé.
C’est du revenu imposable, donc, a priori, avant impôt. Ce qui n’est pas forcément la bonne information : quand on s’intéresse à la distribution des revenus, on sous-entend en général que la redistribution par l’impôt pourrait corriger une partie des disparités. Or là, l’effet de la redistribution n’est pas pris en compte.
@jck
Eueueuh !
Vous êtes certain que vous avez tout lu dans le document que vous donnez en référence ?
Parce que le tableau (en bas de p. 46) de l’Insee, en la personne de Julie Solard, donne bien moyenne et médiane et fournit même le rapport entre elles dans les différentes classes (classe, entendue, bien évidemment au sens d’un découpage statistique,…). Où est la fraude ?
Parce que, même au sein des très hauts revenus, ceux-ci sont fortement concentrés sur quelques personnes (p. 46)
Parce que 0,1% de la population s’approprie 4,6% de la croissance (déclarée) des revenus entre 2004 et 2007 (p. 58).
Parce qu’effectivement, l’Insee signale (intertitres, pp. 57-58) :
– une explosion du nombre de personnes riches entre 2004 et 2007…
– … accompagnée d’une explosion des revenus touchés par les personnes à très hauts revenus…
– … d’où une augmentation des inégalités par le « très haut »
(NB : l’Insee est le spécialiste mondial des intertitres qui s’enchaînent !)
On retrouve ce genre de données dans le discours de J.P. Brard à l’assemblée, sur la répartition des richesses en France :
http://www.youtube.com/watch?v=Y...
@Simplicissimus:
J’ai bien lu le document au complet, allez voir page 59, tableau 12. L’illustration de l’evolution du revenu par classe est faite en utilisant la moyenne qui ne veut rien dire pour ce type de distribution (re: Mandelbrot et d’autres).
Et ca continue au tableau 13 ==> "en 2004,les plus aises detenaient 0.5% des revenus. Leur part a progresse de 26% en 3 ans" ==> Certainemebnt plus impressionnant que de dire qu’il est passe de 0.5% a 0.63%.
De plus, l’effet redistribution n’est pas pris en compte comme le note Antoine B.
@jck
Oui, je me doutais bien que vous l’aviez lu !-:)
La redistribution, du moins l’imposition sur les revenus (activités et patrimoine), est abordée en p. 51 et dans le tableau 7, en haut de la page suivante où l’on trouve des éléments sur la distribution des taux d’imposition. Je ne suis pas certain que cela modifie sensiblement les conclusions.
Mais, c’est là aussi (dans ces tranches) qu’il faudrait disposer d’une étude sur l’impact du bouclier fiscal.
Enfin, je reviens sur la "fraude", dont je comprends mieux la signification après votre deuxième commentaire. Le message de J. Solard est clair : il y a une augmentation des inégalités par le « très haut » (c’est le dernier intertitre qui joue le rôle de conclusion).
De ce point de vue, il est non seulement logique mais pratiquement indispensable de s’appuyer sur la moyenne plutôt que sur la médiane. Comme le répète tous les enseignements de statistiques descriptives (dont celui que je dispense) :
– "la moyenne est sensible aux valeurs extrêmes, la médiane ne l’est pas".
On peut même dire que, dans ce contexte, retenir la médiane est un choix pseudo-technique, mais à vocation parfaitement idéologique : par construction, elle est faite pour ne pas bouger.
Elle s’intéresse au revenu de l’individu du milieu. Or le classement (le rang) de celui-ci ne sera absolument pas modifié si l’individu le plus riche voit son revenu multiplié par un million. C’est même vrai, si TOUS les individus situés au dessus de lui voient leur revenu multiplié par 10 ! (dans le cas d’un effectif impair, si on veut chicaner, et tous sauf celui juste au dessus dans le cas pair).
Il y a un gros biais sémantique dans l’interprétation des chiffres de cette étude :
On parle des "plus aisés" comme s’ils s’agissait des mêmes entre les deux périodes, même si on apprend qu’entre 2006 et 2007 ils ne sont que 50 % à faire partie des deux échantillons.
Ce qu’il faudrait dire, c’est que les 2 000 foyers les plus aisés ont gagnées 40 % de moins que les 2 000 foyers les plus aisés de 2007 mais qu’on ne dispose pas d’information sur le devenir des revenus des 2 000 foyers les plus aisés de 2004.
Il faut aussi évoquer qu’entre 2004 et 2007 la bourse et les prix immobiliers ont eu une progression de l’ordre de 70 % ; Le chiffre évoqué n’est donc pas étonnant dans la mesure où les plus aisés tirent la plus grand partie de leur revenus de leur capital.
Conclure par une augmentation des inégalités comme le fait alter-eco (et pas l’insee) c’est soit être malhonnête, soit ne pas avoir compris l’étude.
Pour pouvoir le faire, il aurait fallu une étude qui couvre l’intégralité d’un cycle économique : par exemple 2000 – 2007 ou 2003 – 2009 et qui s’intéresse aux individus définis comme les "plus aisés" en début de période, c’est à dire sans changer le périmètre de l’étude chaque année.
@Simplicissimus:
"la moyenne est sensible aux valeurs extrêmes, la médiane ne l’est pas"
Exactement, c’est pour cela que la moyenne n’est pas representative de la "classe" des gens aises pour ce type de distribution statistique (pareto)et quand on analyse l’extreme de la distribution parce que la grande majorite de la "classe" est en dessous de la moyenne. (voir Mandelbrot)
@jck :
Personnellement, dans le cas présent je trouve la moyenne beaucoup plus instructive que la médiane : ce tableau met en valeur les extrêmes (de part le découpage des lignes), choisir la médiane reviendrait à manipuler les chiffres pour gommer les différences.
De plus le terme « fraude » est peut-être un tantinet exagéré…
S’il s’agit de revenus déclarés,il n’est peut-être pas utile de s’exciter sur les décimales pour ce genre de répartition. L’ampleur des revenus non déclarés tout particulièrement dans la tranche 48 000 / 118 000 (car paradoxalement au-dessus la fraude n’est pas nécessaire, au dessous difficile à réaliser pour le salarié lambda) ne peut rendre compte de la réalité des revenus disponibles.
D’autre part , ne pas distinguer revenus du travail et revenus du capital n’éclaire pas le débat.Comme souvent dans Alternatives , polémique et surtout incertain
Des chiffres sur les revenus après impôts sont disponibles sur le site de l’OCDE (oecd.org) il me semble, mais le site est inaccessible pour le moment 🙁
Je me rappelai cette étude pour avoir fait un article dessus en décembre 2009!
Alter éco fait du réchauffé!
http://www.insee.fr/fr/themes/do...
Notons cependant que l’étude de l’INSEE porte non pas sur ;la période 2004 2007 mais sur la période 1996 / 2007. Pourquoi ne pas reprendre cette durée qui donne beaucoup plus de sérieux?
il se trouve que sur la période 1996/2007 le revenu moyen du premier décile a augmenté plus fort que les autres (21 contre 17%) mais que le rapport inter décile a baissé (CAD que les inégalités ont diminué) quelque peu….sauf entre 2004 et 2007 (voir graphique 3 sur le document en lien) et comme par hasard ce sont ces dates que choisi Alter Eco
@Verel
Tout d’abord, pour l’éventuel "réchauffé", ce n’est pas AlterÉco, mais bien l’Insee dont il s’agit. Le mensuel ne fait que reprendre l’étude publiée dans l’édition 2010 de "Les revenus et le patrimoine des ménages".
Ensuite, contrairement aux apparences, les sources sont très différentes. Dans le cas de l’étude "longue" (1996/2007), il s’agit d’une enquête par sondage, effectuée sur un panel de 10.000 ménages (cf. note méthodo du document que vous citez en lien). Ce qui ne peut rien donner de sérieux au niveau des "très hauts revenus" où se situe l’étude de J. Solard : là on parle du fractile à 99,99%, soit 1 pour 10.000 ménages. D’ailleurs l’étude de Jérôme Pujol et Magda Tomasini ne descend pas en dessous d’une comparaison des déciles (10% de la population).
L’étude de J. Solard porte sur la totalité des déclarations de revenus, soit de l’ordre de plusieurs dizaines de millions de ménages fiscaux. (le 1 pour 10.000 des ménages concerne environ 5.800 personnes – c’est dans le texte – d’où un nombre de personnes par ménage fiscal de l’ordre de 2 à 3).
L’exploitation statistique exhaustive des déclarations de revenus est, je crois, assez récente et ne devait pas être mise en place en 1996.
@henriparisien
Il ne s’agit, en effet, pas d’un panel avec un suivi longitudinal des ménages, mais de la comparaison des fractiles à deux périodes distinctes. Et l’étude est claire là-dessus, notamment lorsqu’elle parle des "entrants" et des "persistants".
@jck
Nous sommes donc d’accord 😉 puisqu’il ne s’agit justement pas de donner une valeur "représentative de la classe des gens aisés", mais de s’intéresser :
1. à la classe extrême,
2. à l’intérieur de celle-ci, à l’extrêmité supérieure de la classe.
Et d’ailleurs, le rapport (Moyenne/Médiane) qui est fourni dans le tableau 2 est donné ici comme indicateur de la dissymétrie de la distribution. Il mesure très directement le fait que les (très) hautes valeurs tirent la moyenne vers le haut.
Ce qui, avec le fait que ce tirage vers le haut a eu tendance à s’accroître, constitue le fond de l’article,
(mais j’ai l’impression de me répéter…)
Pure coincidence, mais voila un ex. de fraude statistique ==> en trafiquant le revenu de 2 personnes, on montre que le revenu de la "classe" a quintuple, alors qu’il est en baisse de 8.7%
http://www.bloomberg.com/news/20...
Eueueuh !
Décidément, on ne comprend pas les mêmes choses !
Apparemment, il s’agit d’une erreur dans la détermination de l’indice "National Average Wage Index" (NAWI), calculé annuellement pour la revalorisation des pensions versées par la Sécurité sociale états-unienne.
Cet indice est calculé par la Sécu à partir d’un échantillon d’environ 151.000 travailleurs (chiffres exacts ici :
http://www.ssa.gov/OACT/COLA/awi...
)
et à partir d’un bordereau dit W-2 (formulaire consultable, là :
http://www.irs.gov/pub/irs-pdf/f...
déclaration individuelle de revenus transmise à la Sécurité sociale et aux services de la fiscalité locale et fédérale (IRS))
Or, dans la strate des plus de 50 millions de dollars annuels de revenu, sur les 74 travailleurs de l’échantillon NAWI, deux personnes étaient titulaires en 2009 de revenus supérieurs à 32 milliards de dollars. Ce chiffre astronomique résulterait de la multiplicité des déclarations fournies par les déclarants.
Ces valeurs extrêmes sont passées à travers tout le processus de production de l’indice. Elles n’ont été détectées, traitées comme incorrectes, et donc éliminées du calcul, qu’après une première publication de l’indice. D’où le piteux communiqué de la Sécu.
Au passage, ceci laisse entrevoir quelques grosses lacunes dans le processus de production et pourrait justifier l’extrême discrétion du bureau de la Sécurité sociale sur la nature exacte de l’erreur et sur sa non-détection.
Où est la "fraude" ?
Où est le "trafic" ?
Qui est ce méchant "on" qui voudrait à toutes forces "montrer" que les très riches se gavent comme des porcs ?
– Oh le beau cas ! s’exclamerait le Dr Pécule devant un tel loupé de la production statistique. Et merci à jck de l’avoir signalé : je vais de ce pas l’incorporer dans le musée des horreurs que l’on peut laisser passer quand "on ne regarde pas" les données sur lesquelles on travaille.
Enfin, il est certain qu’il y en a quelques uns qui doivent se faire méchamment frotter les oreilles !
@Simplicissimus, dans votre réponse à henriparisien :
l’article d’Altereco s’intitule : "Des riches de plus en plus riches". Le sous-titre est : "
Bonne nouvelle: l’Insee a publié de nouvelles données sur les plus aisés. Mauvaise nouvelle: ils s’enrichissent beaucoup plus vite que le reste de la population."
Clairement, l’article laisse entendre que les populations sont homogènes et que croissance de 40% des revenus du fractile signifie croissance de 40% des revenus des individus.
C’est facheux.
Un commentaire tardif pour non initié : ne pas oublier de préciser que les revenus déclarés du tableau initial sont les revenus du foyer fiscal par "unité de consommation". Exemple : ma déclaration fiscale 2009 est de 65k€, marié, 2 enfants, mon revenu est de 65/2.3=28 k€, je suis dans les 90% (revenus entre 0 et 35.7k€).
De toute maniere, je vois deux biais dans ces tableaux:
1. Lorsque l’on s’intéresse a 0,01% de la population, il semble souhaitable de montrer qui la compose et comment sa composition évolue;
2. Les revenus declarés notamment pour les classes faisant l’horreur des commentateurs dépendent me semble t il de la politique de dividende des entreprises qui composent leur portefeuille boursier. Il me semble qu’il y a incoherence a penser que leur revenu du capital peut avoir augmenter alors que la part de la plus value allant au capital est constante.
Mais je ne suis qu’epicier, pas satisticien.